![Speculative Decoding: Acelera Inferencia LLM 2-4x en Producción [Guía Completa 2025] | BCloud Consulting](/images/nextImageExportOptimizer/speculative-decoding-hero-opt-1920.WEBP)
El Cuello de Botella de Inferencia LLM en 2025
49.5x crecimiento en tokens de inferencia de Google en solo 12 meses
De 9.7 billones de tokens en abril 2024 a 480 billones en abril 2025 (The Next Platform, 2025)
Si eres Engineering Manager o ML Engineer en una startup SaaS, probablemente has visto cómo tus costes de inferencia LLM se han disparado en los últimos 6 meses. El mercado de APIs de modelos de lenguaje pasó de invertir en inferencia, dejando el entrenamiento en segundo plano.
Pero hay un problema más grave que el coste: la latencia mata la experiencia de usuario. Cuando tu chatbot tarda 3-5 segundos en responder, el usuario se va. Cuando tu asistente de código genera sugerencias después de que el developer ya escribió la línea, es inútil. Cuando tu agente autónomo tarda 30 segundos en completar una tarea que debería ser instantánea, pierdes credibilidad.
📊 Dato clave:
El porcentaje de cómputo empresarial dedicado a inferencia (en lugar de entrenamiento) creció del 29% al 49% en solo un año. Casi la mitad del presupuesto de infraestructura IA ahora se consume en inferencia, no en entrenar modelos.
Fuente: Menlo Ventures, 2025 Mid-Year LLM Market Update
La buena noticia: existe una técnica que permite acelerar la inferencia de LLMs entre 2x y 4x sin sacrificar calidad de outputs. Se llama Speculative Decoding (decodificación especulativa), y empresas como Google, Meta e IBM la usan en producción para servir miles de millones de requests diarios.
En este artículo te muestro exactamente cómo funciona speculative decoding, cómo implementarlo con vLLM o TensorRT-LLM en producción, qué configuraciones usar según tu caso de uso (chatbots vs generación de código vs agentes), cuándo NO usarlo, y cómo calcular el ROI real considerando el trade-off entre latencia y throughput.
💡 Nota: Si prefieres que implemente speculative decoding en tu infraestructura LLM existente, mi servicio MLOps & Deployment incluye optimización completa de inferencia con benchmarking, configuración y monitoreo.
Speculative Decoding Production Checklist
Checklist de 30 puntos para implementar speculative decoding en producción sin errores. Incluye configuraciones vLLM, troubleshooting acceptance rate, y decisiones draft model.
Descarga instantánea por email. Sin spam.
1. El Cuello de Botella de Inferencia LLM en 2025
Para entender por qué speculative decoding es crítico ahora, necesitas ver el contexto completo del mercado de inferencia en 2025.
► El Shift Masivo: De Entrenamiento a Inferencia
Durante años, el presupuesto de IA/ML empresarial se concentró en entrenamiento: comprar GPUs A100/H100, contratar data scientists, iterar modelos custom. Pero en 2024-2025 todo cambió.
| Métrica | 2023 | 2024 | 2025 | Cambio |
|---|---|---|---|---|
| % Cómputo Inferencia | 18% | 29% | 49% | +31pp |
| Gasto API Modelos | N/A | Estimado bajo | Crecimiento significativo | +140% |
| Tokens Inferencia Google/mes | N/A | 9.7 billones | 480 billones | +49.5x |
Este cambio tiene una razón simple: los modelos foundation ya existen. OpenAI GPT-4, Anthropic Claude, Meta Llama, Google Gemini. Ya no necesitas entrenar un modelo desde cero para tener capacidades avanzadas. Solo necesitas fine-tunearlo (si acaso) y desplegarlo en producción.
► El Problema: Latencia Mata Experiencia de Usuario
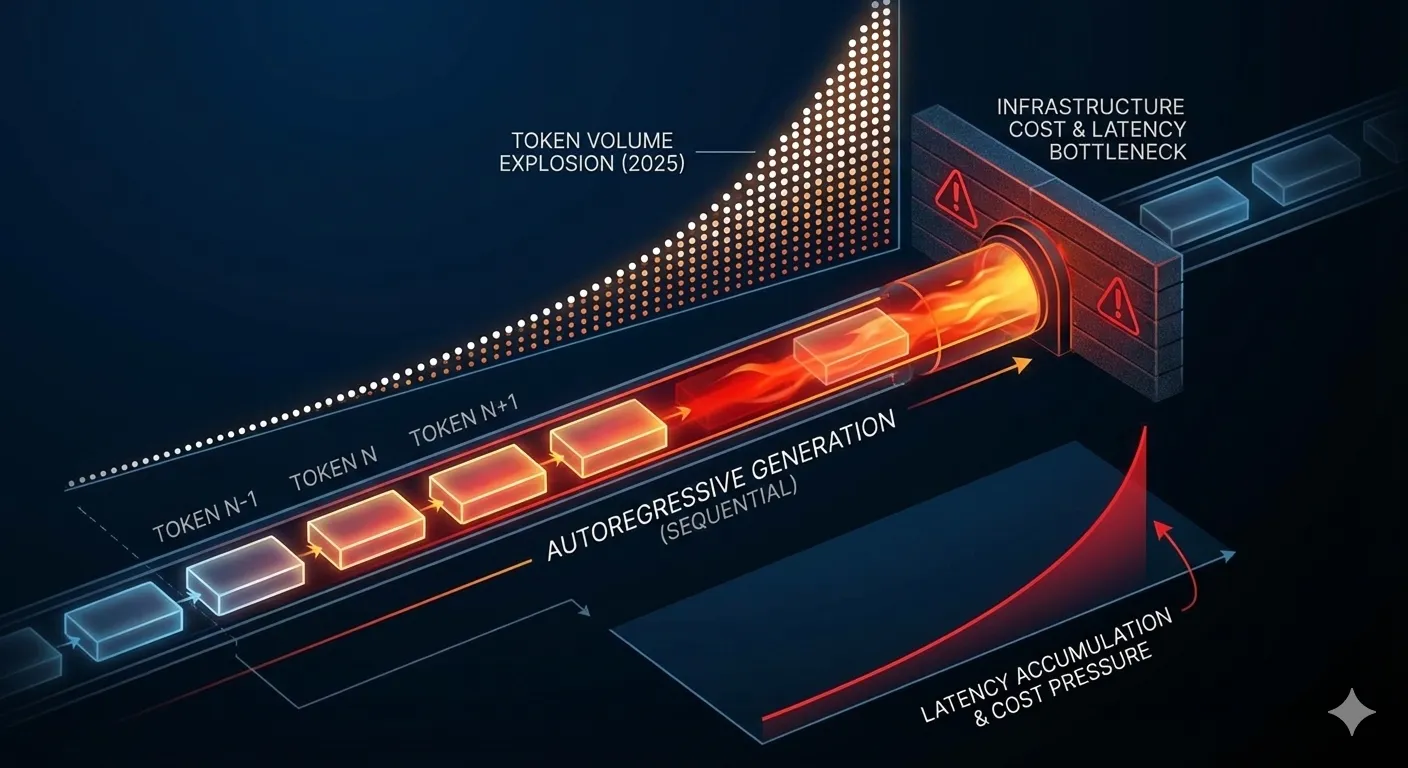
Pero desplegar modelos grandes en producción introduce un cuello de botella crítico: la generación autoregresiva de tokens es inherentemente lenta.
⚠️ Problema técnico: Los LLMs generan texto token por token de forma secuencial. Cada token requiere un forward pass completo del modelo. Para generar 100 tokens necesitas 100 forward passes. Si cada forward pass tarda 50ms, estás hablando de 5 segundos totales solo para generar una respuesta corta.
Este problema se amplifica con modelos grandes. Un Llama 3.1 70B o GPT-4 requiere múltiples GPUs con tensor parallelism, lo que añade overhead de sincronización. El resultado:
- Chatbots lentos: 3-5 segundos de latencia hacen que el usuario cierre la ventana
- Code completion inútil: Sugerencias que llegan después de que el developer escribió la línea
- Agentes bloqueados: Workflows multi-step que tardan minutos en lugar de segundos
- Costes descontrolados: Más tiempo de GPU = más coste por request
► La Presión Económica: Costes de Inferencia
Además de la latencia, está el coste directo. Aunque el precio por token ha caído dramáticamente (reducción de 1000x en 3 años según Andreessen Horowitz), el volumen ha crecido exponencialmente, compensando la reducción de precio unitario.
📉 Paradoja LLMflation:
GPT-3 en noviembre 2021 costaba $60 por millón de tokens. En 2024, Llama 3.2 3B (mismo MMLU score) cuesta $0.06 por millón de tokens. Eso es reducción de 1000x.
Pero: El volumen de tokens procesados creció más de 1000x en el mismo período. Empresas que gastaban en inferencia ahora gastan más en términos absolutos, aunque menos por token.
Fuente: a16z, "Welcome to LLMflation", 2024
Para startups SaaS procesando millones de requests al mes, reducir latencia de inferencia un 50% puede significar ahorros tangibles en infraestructura cloud. Para productos de cara al usuario, puede ser la diferencia entre retención y churn masivo.
Alternative Techniques: Cuándo Combinar con Otras Optimizaciones
11. Alternative Techniques: Cuándo Combinar con Otras Optimizaciones
Speculative decoding es una técnica entre muchas. Aquí está cuándo usar cada una y cuándo combinarlas para máximo impacto.
| Técnica | Mejora Latencia | Mejora Throughput | Reduce Memoria | Afecta Calidad | Combina con Speculative |
|---|---|---|---|---|---|
| Speculative Decoding | ✅ 2-4x | ⚠️ Variable | ❌ +5-10% | ✅ Idéntica | - |
| Quantization (INT8/INT4) | ⚠️ +10-30% | ✅ +50-100% | ✅ 50-75% | ⚠️ -2-5% | ✅ Sí |
| Prompt Caching | ✅ 80-95% TTFT | ✅ +200-500% | ❌ +10-20% | ✅ Idéntica | ✅ Sí |
| Flash Attention | ⚠️ +20-40% | ✅ +30-50% | ✅ 30-50% | ✅ Idéntica | ✅ Sí |
| Model Distillation | ✅ 3-10x | ✅ 3-10x | ✅ 70-90% | ❌ -5-15% | ⚠️ Redundante |
| Continuous Batching | ⚠️ +0-20% | ✅ +100-300% | ➖ Neutral | ✅ Idéntica | ✅ Sí |
► Stacking Optimizations: Combinaciones Ganadoras
🎯 Combinación Óptima Latency-Critical:
- Speculative Decoding (2-4x latency reduction)
- + Prompt Caching (80-95% TTFT reduction en requests repetidos)
- + Flash Attention 2 (20-40% additional speedup, gratis en vLLM)
- + INT8 Quantization (trade-off: +30% latency but 2x throughput capacity)
- Resultado combinado: 5-8x latency improvement end-to-end, quality loss
🎯 Combinación Óptima Throughput-Critical:
- Continuous Batching (vLLM PagedAttention, 100-300% throughput)
- + INT4 Quantization (AWQ/GPTQ, 3-4x throughput, 75% memory reduction)
- + Tensor Parallelism (multi-GPU scaling linear)
- + NO Speculative Decoding (degrada throughput en high batch)
- Resultado combinado: 10-20x throughput capacity vs baseline
► Decisión Framework por Prioridad
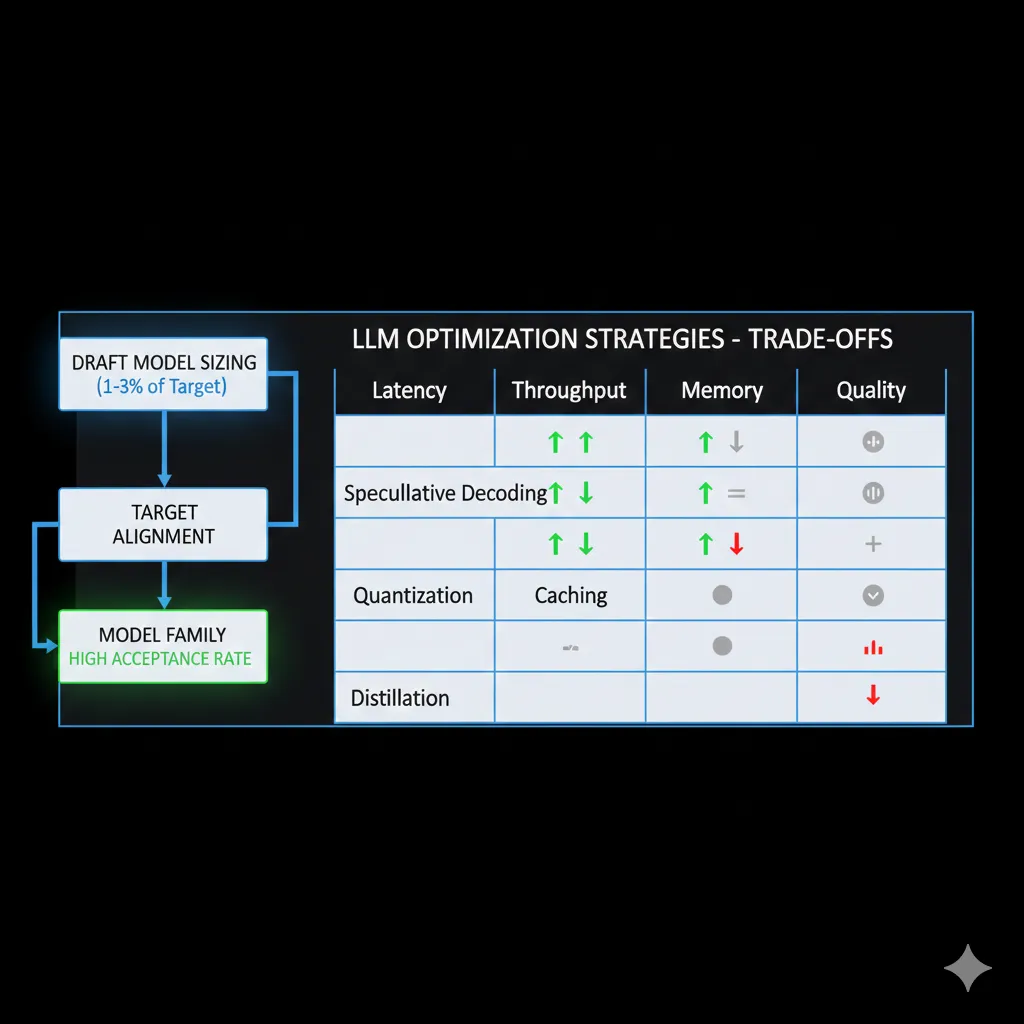
Guía rápida decisión:
- Prioridad #1 Latencia individual: Speculative Decoding + Prompt Caching
- Prioridad #1 Throughput aggregate: Continuous Batching + Quantization (NO speculative)
- Prioridad #1 Memoria limitada: Quantization INT4 + Model Distillation (NO speculative)
- Prioridad #1 Calidad zero-loss: Speculative + Prompt Caching + Flash Attention (NO quantization)
Draft Model Selection: La Clave del Éxito
3. Draft Model Selection: La Clave del Éxito
El factor más crítico para el rendimiento de speculative decoding es elegir el draft model correcto. Un draft model mal seleccionado puede resultar en acceptance rates tan bajos que el sistema es más lento que generación autoregresiva normal.
► Sizing Óptimo: 1.64%-5% del Target Model
La investigación académica muestra que los draft models efectivos suelen ser entre 1.64% y 5% del tamaño del target model en parámetros.
| Target Model | Parámetros Target | Draft Model Recomendado | Parámetros Draft | Ratio |
|---|---|---|---|---|
| Llama 2-Chat 7B | 7B | 115M custom draft | 115M | 1.64% |
| Llama 3.1 8B Instruct | 8B | 150M custom draft | 150M | 1.88% |
| Llama 3.1 70B Instruct | 70B | Llama 3.2 1B | 1B | 1.43% |
| Phi-3-mini | 3.8B | 50M custom draft | 50M | 1.32% |
| Qwen 2.5 14B | 14B | Qwen 2.5 0.5B | 500M | 3.57% |
Regla práctica: Para modelos de 7B-70B, busca draft models de 100M-1B parámetros. Más grande que eso y pierdes velocidad. Más pequeño y el acceptance rate cae demasiado.
⚠️ Trade-off crítico: Draft models más grandes tienen mejor acceptance rate (predicciones más cercanas al target), pero son más lentos de ejecutar. El sweet spot suele estar en 1-3% del tamaño del target.
► Model Family Alignment: Usa la Misma Arquitectura
El draft model debe ser de la misma familia arquitectónica que el target model para maximizar alignment y acceptance rate.
Combinaciones recomendadas:
- Target: Llama 3.1 70B → Draft: Llama 3.2 1B o 3B
- Target: Qwen 2.5 14B/32B → Draft: Qwen 2.5 0.5B o 1.5B
- Target: Mistral 7B → Draft: Mistral tiny (si disponible) o custom distilled
- Target: Granite 20B Code → Draft: Granite 3B Code
Por qué importa: Modelos de la misma familia comparten tokenizer, embeddings, y arquitectura de atención. Esto significa que sus distribuciones de probabilidad tienen mayor overlap, resultando en acceptance rates más altos (típicamente 0.6-0.7 vs 0.3-0.4 con familias diferentes).
► Acceptance Rate Threshold: El KPI Crítico
El acceptance rate (tasa de aceptación) es el porcentaje de tokens especulativos que el target model acepta. Es el KPI más importante para medir si speculative decoding está funcionando.
📊 Acceptance Rates Típicos por Uso:
- Conversational AI: 0.65-0.75 (65-75%) - Alto porque lenguaje natural es predecible
- Code generation: 0.55-0.70 (55-70%) - Variable según lenguaje de programación
- Technical Q&A: 0.50-0.65 (50-65%) - Vocabulario técnico reduce alignment
- Creative writing: 0.45-0.60 (45-60%) - Menos predecible por naturaleza
⚠️ Threshold mínimo: Si tu acceptance rate está por debajo de 0.50 (50%), speculative decoding probablemente es más lento que autoregressive normal. El overhead de ejecutar el draft model + verification no compensa el bajo approval de tokens.
Qué hacer si acceptance rate
- Cambiar a un draft model más grande (↑ parámetros hasta 3-5% del target)
- Usar draft model de la misma familia que el target
- Si el target está fine-tuneado, re-entrenar el draft con knowledge distillation
- Reducir num_speculative_tokens (generar menos tokens especulativos por iteración)
- Considerar técnicas alternativas (quantization, prompt caching, chunked prefill)
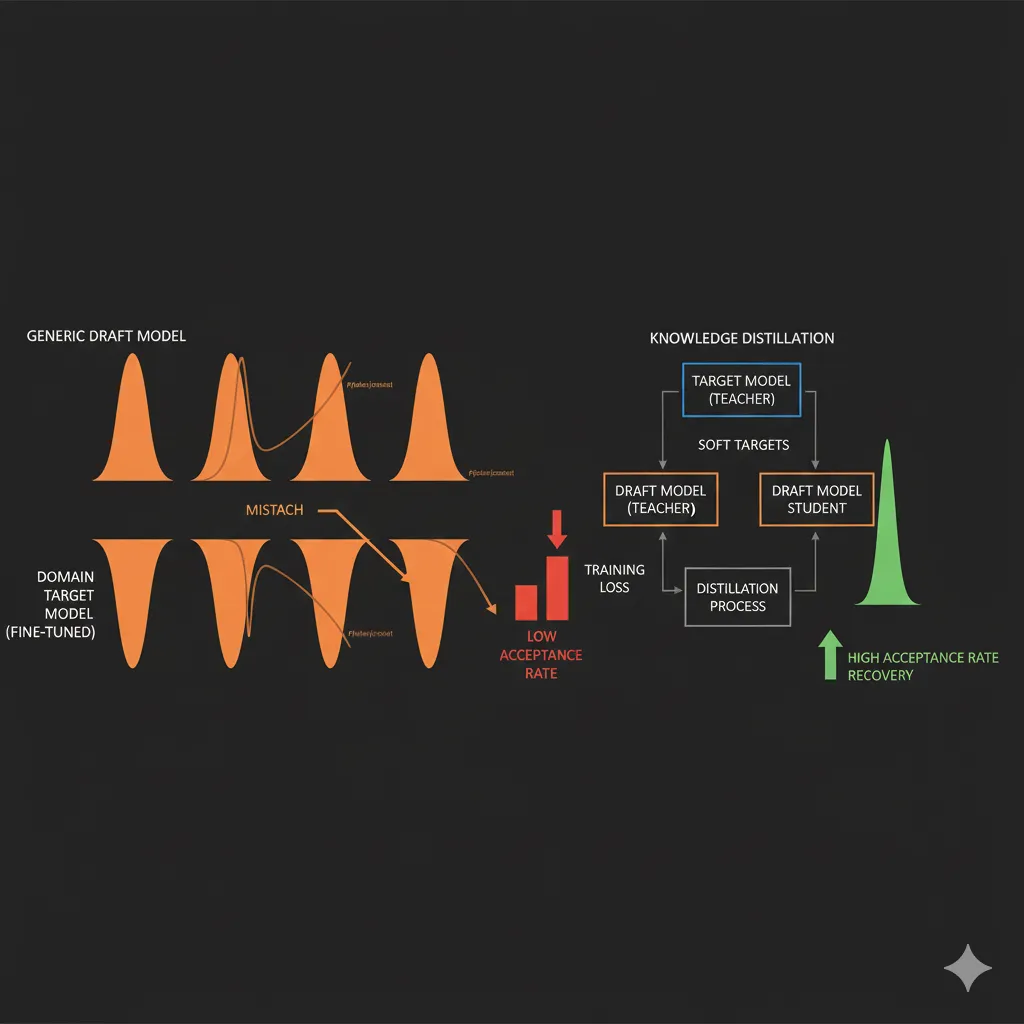
► Domain-Specific Adaptation: El Problema del Fine-Tuning
Un pain point crítico que pocos artículos cubren: cuando fine-tuneas tu target model para un dominio específico, el draft model generic deja de funcionar bien.
🔍 Caso real documentado:
Un equipo fine-tuneó Llama 3.1 70B para queries médicas especializadas. Usaron Llama 3.2 1B generic como draft model. El acceptance rate cayó de 0.68 a 0.32 en queries médicas.
Causa: El target model aprendió vocabulario médico y patrones específicos del dominio, pero el draft model siguió prediciendo como un modelo general. Domain shift masivo.
Fuente: arXiv "Training Domain Draft Models for Speculative Decoding", Marzo 2025
Solución: Re-entrenar el draft model usando knowledge distillation del target model fine-tuneado. Proceso:
- Genera un dataset de outputs del target model fine-tuneado (10k-50k ejemplos)
- Fine-tunea el draft model para imitar las distribuciones del target
- Usa temperature scaling y soft labels para capturar probabilidades, no solo tokens
- Benchmarkea acceptance rate post-distillation (debería recuperar 0.6+)
IBM Research documentó este proceso con Granite 20B Code, entrenando un draft model específico para código que logró acceptance rate de 0.70 vs 0.45 con draft generic.
Production Deployment: Kubernetes + Monitoring
9. Production Deployment: Kubernetes + Monitoring
Implementar speculative decoding en producción requiere infraestructura robusta, monitoreo adecuado y estrategias de rollback si algo sale mal.
► Kubernetes Deployment con vLLM
Configuración production-ready para desplegar vLLM con speculative decoding en Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-speculative-llama70b
namespace: ml-inference
spec:
replicas: 2
selector:
matchLabels:
app: vllm-llama70b
template:
metadata:
labels:
app: vllm-llama70b
spec:
containers:
- name: vllm-server
image: vllm/vllm-openai:v0.6.3
args:
- --model
- meta-llama/Meta-Llama-3.1-70B-Instruct
- --speculative-model
- meta-llama/Llama-3.2-1B
- --num-speculative-tokens
- "5"
- --gpu-memory-utilization
- "0.90"
- --tensor-parallel-size
- "4"
- --dtype
- bfloat16
- --max-model-len
- "8192"
- --port
- "8000"
ports:
- containerPort: 8000
name: http
resources:
requests:
nvidia.com/gpu: 4
limits:
nvidia.com/gpu: 4
env:
- name: HF_TOKEN
valueFrom:
secretKeyRef:
name: huggingface-token
key: token
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 120
periodSeconds: 30
readinessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: vllm-service
namespace: ml-inference
spec:
selector:
app: vllm-llama70b
ports:
- protocol: TCP
port: 80
targetPort: 8000
type: LoadBalancer
✅ Configuración clave: Este deployment usa 4 GPUs con tensor parallelism para el target model (Llama 70B). El draft model (1B) ejecuta en fracción de los mismos GPUs. La configuración `gpu-memory-utilization=0.90` reserva 10% headroom para KV caches.
► Monitoring con Prometheus + Grafana
Métricas críticas para monitorear speculative decoding en producción:
KPIs esenciales:
- Acceptance rate: % tokens especulativos aceptados (target: >0.55)
- Latency P50/P90/P99: Distribución latencia requests (target:
Script Python para exponer acceptance rate a Prometheus:
import time
import requests
from prometheus_client import start_http_server, Gauge
# Métricas Prometheus
acceptance_rate_gauge = Gauge(
'vllm_speculative_acceptance_rate',
'Acceptance rate de tokens especulativos'
)
latency_p50_gauge = Gauge(
'vllm_latency_p50_seconds',
'Latencia P50 en segundos'
)
goodput_gauge = Gauge(
'vllm_goodput_tokens_per_second',
'Tokens válidos generados por segundo'
)
def fetch_vllm_metrics():
"""
vLLM expone métricas en /metrics endpoint (Prometheus format)
pero acceptance rate requiere parsing custom de logs o stats API
"""
try:
# Workaround: vLLM no expone acceptance rate directamente
# Necesitas enable stats logging y parsear
response = requests.get('http://localhost:8000/stats')
stats = response.json()
# Calcular acceptance rate desde stats
total_speculative = stats.get('total_speculative_tokens', 0)
accepted = stats.get('accepted_speculative_tokens', 0)
acceptance_rate = accepted / total_speculative if total_speculative > 0 else 0
acceptance_rate_gauge.set(acceptance_rate)
latency_p50_gauge.set(stats.get('latency_p50', 0))
# Goodput = accepted tokens / time
goodput = accepted / stats.get('total_time_seconds', 1)
goodput_gauge.set(goodput)
except Exception as e:
print(f"Error fetching metrics: {e}")
if __name__ == '__main__':
# Exponer métricas en puerto 9090 para Prometheus scraping
start_http_server(9090)
while True:
fetch_vllm_metrics()
time.sleep(10) # Scrape cada 10 segundos
⚠️ Limitación vLLM: vLLM versiones

► Alerting Thresholds y Rollback Strategy
Define alertas para detectar degradación y rollback automático si es necesario:
| Métrica | Threshold Warning | Threshold Critical | Acción |
|---|---|---|---|
| Acceptance Rate | |||
| Latency P99 | >3s | >5s | Rollback a autoregressive |
| Error Rate | >2% | >5% | Rollback inmediato |
| GPU Memory | >92% | >97% | Reducir num_speculative_tokens |
✅ Rollback strategy: Mantén deployment autoregressive normal en standby. Si acceptance rate cae
Qué es Speculative Decoding y Por Qué Funciona
2. Qué es Speculative Decoding y Por Qué Funciona
Speculative decoding es una técnica de optimización de inferencia que permite generar múltiples tokens en paralelo en lugar de uno por uno, acelerando la generación entre 2x y 4x sin perder calidad.
► Las Dos Observaciones Clave de Google Research
La técnica fue desarrollada originalmente por Google Research en 2022 y publicada en el paper "Fast Inference from Transformers via Speculative Decoding". Se basa en dos observaciones críticas:
Observación #1: No todos los tokens son igualmente difíciles de predecir
Algunos tokens son triviales (artículos, preposiciones, palabras comunes en contexto obvio). No necesitas un modelo de 70B parámetros para predecir "de" después de "el problema". Un modelo pequeño de 1B puede hacerlo igual de bien.
Observación #2: La generación LLM es memory-bound, no compute-bound
El cuello de botella real no es la capacidad de cómputo de la GPU, sino la velocidad de lectura de pesos del modelo desde memoria (HBM → compute cores). Si puedes verificar múltiples tokens en un solo forward pass, aprovechas el ancho de banda de memoria de forma más eficiente.
Combinando estas dos observaciones, Google desarrolló speculative decoding: usar un modelo pequeño y rápido (draft model) para generar varios tokens candidatos especulativos, y luego usar el modelo grande (target model) para verificarlos todos en un solo forward pass paralelo.
► Cómo Funciona: Draft + Verification en Paralelo
El algoritmo tiene cuatro pasos principales:
- Generación especulativa (draft model): Un modelo pequeño y rápido (por ejemplo, Llama 3.2 1B) genera K tokens candidatos de forma autoregresiva normal. Típicamente K=3-8 tokens.
- Verificación paralela (target model): El modelo grande (Llama 3.1 70B) recibe los K tokens como entrada y calcula las probabilidades de todos ellos en un solo forward pass paralelo.
- Aceptación/rechazo: Se comparan las probabilidades del draft model vs target model para cada token. Si coinciden (dentro de un threshold), el token se acepta. Si difieren, se rechaza ese token y todos los siguientes.
- Continuación: Se acepta la secuencia válida más larga y se repite el proceso hasta completar la generación.
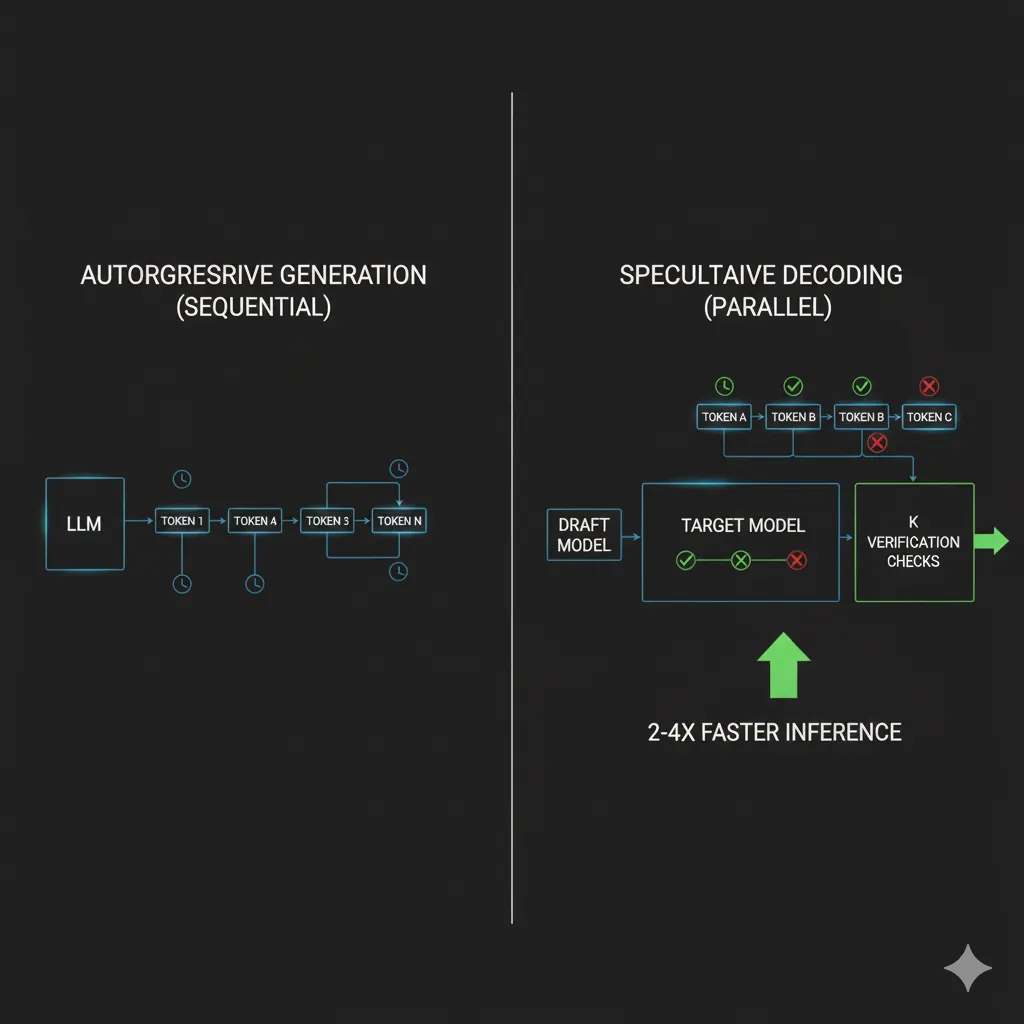
La magia está en el paso 2: verificar K tokens en paralelo es casi tan rápido como verificar 1 token, porque el cuello de botella es cargar los pesos del modelo en memoria, no hacer los cálculos. Si aceptas 3 de 4 tokens especulativos en promedio, has generado 3 tokens válidos con el coste de 1 forward pass del modelo grande + 4 forward passes del modelo pequeño (que es 20-50x más rápido).
► Matemáticamente Idéntico al Autoregressive Normal
Un aspecto crítico que diferencia speculative decoding de otras técnicas de optimización (como beam search truncado o sampling con temperature alto) es que produce exactamente la misma distribución de probabilidad que generación autoregresiva normal.
✅ Garantía matemática: El algoritmo de verificación está diseñado para que, en expectation, la distribución de tokens generados sea idéntica a si hubieras usado solo el target model de forma autoregresiva. No hay pérdida de calidad, solo speedup.
Esto fue validado por Google Research en sus benchmarks originales de traducción y summarization, donde lograron 2x-3x speedup sin degradación en métricas BLEU/ROUGE.
📊 Benchmark Google AI Overviews (2024):
Google implementó speculative decoding en Google Search AI Overviews, procesando miles de millones de queries diarias. Resultados:
- Latencia reducida 2x-3x en promedio
- Throughput mantenido (batch size pequeño típico en search)
- Calidad outputs matemáticamente idéntica
- Costes infraestructura reducidos por menor tiempo GPU por query
Fuente: Google Research Blog, "Looking back at speculative decoding", 2024
Red Hat Speculators: El Futuro de Speculative Decoding (Nov 2025)
12. Red Hat Speculators: El Futuro de Speculative Decoding (Nov 2025)
El 19 de noviembre 2025, Red Hat lanzó Speculators, un framework que resuelve la fragmentación del ecosistema speculative decoding y marca el futuro de la técnica.
► El Problema: Fragmentación del Ecosistema
Antes de Speculators, cada framework de inferencia tenía formato propietario para draft models:
- vLLM: Custom format, no standardized metadata
- TensorRT-LLM: Engine files compiled específicos NVIDIA GPUs
- llama.cpp: GGUF format, no compatible cross-platform
- PyTorch: Custom implementations sin interoperabilidad
⚠️ Consecuencia:
Equipos ML debían entrenar draft models múltiples veces (uno por framework), gestionar hyperparameters manualmente sin guidelines, y debugging era nightmare por falta de métricas standardizadas. Adoption barrier masivo para producción.
► La Solución: Hugging Face Format Standardization
Red Hat Speculators introduce tres innovaciones clave:
1. Formato Hugging Face Estándar:
Todos los draft models (speculators) se publican en Hugging Face con metadata standardizado: target model compatible, num_speculative_tokens recomendado, acceptance rate benchmarks.
2. Hyperparameter Guidelines Automatizadas:
Cada speculator incluye config file con hyperparameters óptimos pre-calculados para diferentes use cases (conversational, code, long-context). Elimina guess-work.
3. Métricas Tracking Standardizadas:
Framework expone acceptance rate, goodput, latency P50/P90/P99 en formato Prometheus compatible. Observability out-of-the-box.
► Modelos Speculators Pre-Entrenados (Nov 2025)
Red Hat lanzó 7 speculators production-ready:
| Speculator Model | Target Model | Speedup Low-Latency | Speedup High-Throughput |
|---|---|---|---|
| Llama-3.3-70B-Instruct-speculator | Llama-3.3-70B-Instruct | 2.0-2.7x | 1.3-1.5x |
| Qwen3-32B-speculator | Qwen3-32B | 2.2-2.5x | 1.4-1.6x |
| Llama-4-Maverick-speculator | Llama-4-Maverick | 2.5-2.7x | 1.8-4.9x |
✅ Compatibilidad inmediata vLLM: vLLM 0.6.0+ reconoce automáticamente speculators en Hugging Face format. Solo necesitas especificar el model ID en `speculative_model` parameter. Zero config adicional.
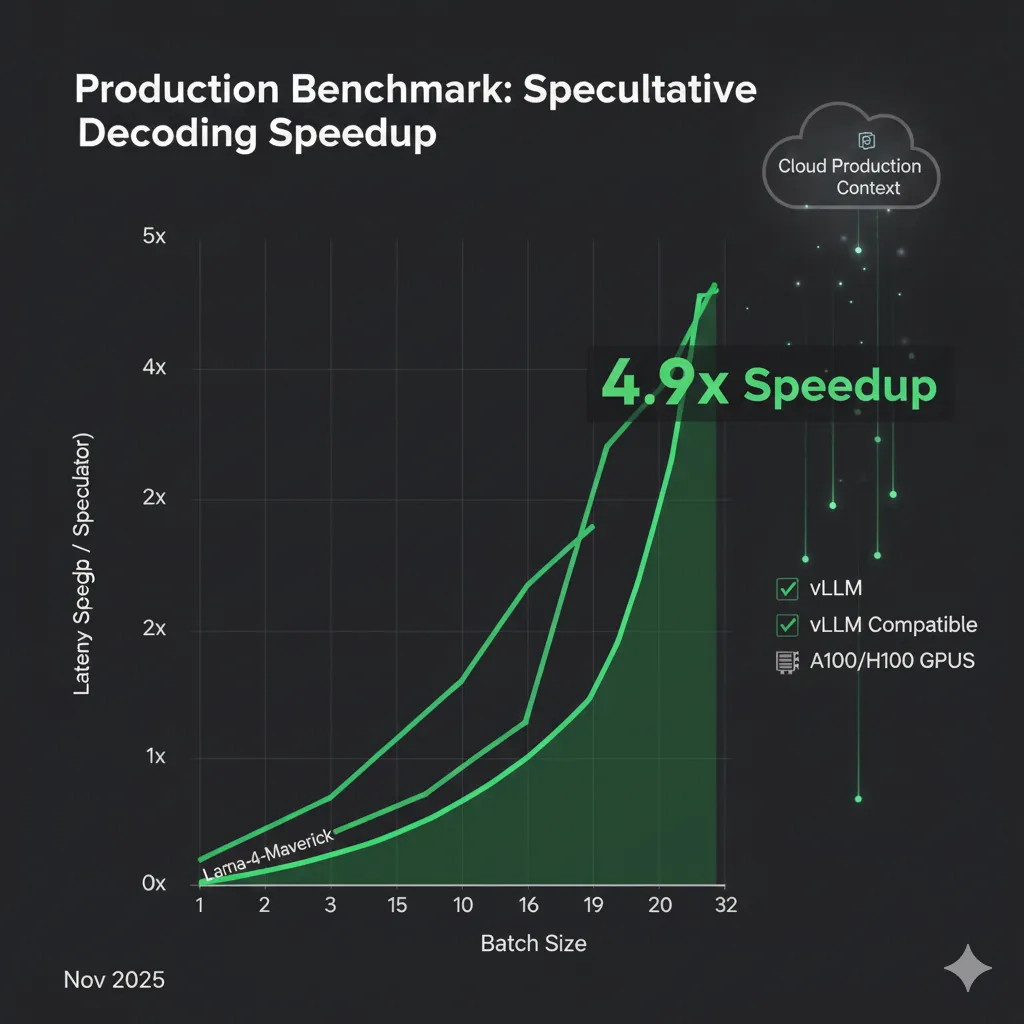
► Benchmarks Production: Llama-4-Maverick 4.9x Speedup
El benchmark más impresionante: Llama-4-Maverick speculator logra hasta 4.9x latency reduction en high-throughput regime, contradiciendo conventional wisdom de que speculative decoding degrada con batch sizes altos.
📊 Breakthrough: Batch Size Scaling Resuelto
Red Hat logró que Llama-4-Maverick mantenga speedup 1.8x-4.9x incluso con batch sizes >16, gracias a optimizaciones:
- Alignment verification parallelizada (reduce overhead de 38% a
Esto marca un turning point: speculative decoding ya NO es solo para low-latency single-request scenarios. Ahora es viable para high-throughput production workloads.
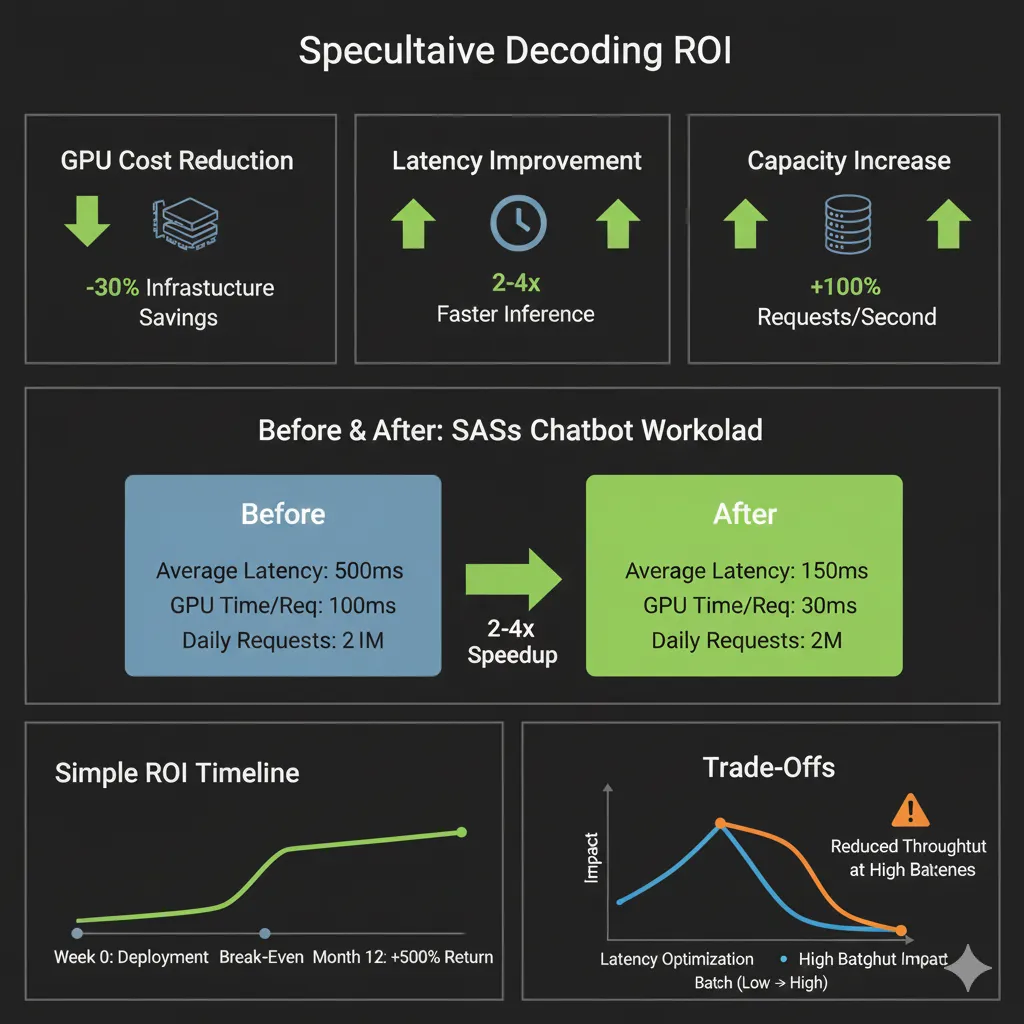
ROI Calculator: Cuándo Vale la Pena Implementar
8. ROI Calculator: Cuándo Vale la Pena Implementar
Implementar speculative decoding tiene costes: engineering time, infraestructura, complejidad. Aquí está el framework para calcular si el ROI justifica la inversión.
► Costes de Implementación
| Concepto | Tiempo Eng. | Infraestructura | Notas |
|---|---|---|---|
| vLLM Draft-Target | 2-5 días | +5-10% GPU mem | Más fácil, producción rápida |
| vLLM EAGLE-3 | 3-7 días | +3-5% GPU mem | Mejor efficiency, no draft separado |
| TensorRT-LLM | 4-6 semanas | +5-10% GPU mem | Max performance, complejidad alta |
| Draft Model Custom Training | 2-4 semanas | GPU training | Solo si domain-specific necesario |
► Beneficios Cuantificables
💰 Fuentes de ahorro/valor:
- Reducción coste GPU: 2-3x speedup = 50-66% menos GPU time per request
- Mejora conversión: Latencia
- Capacity liberada: Mismo hardware sirve 2-3x más requests
- Competitive advantage: User experience superior vs competencia
Ejemplo cálculo startup SaaS chatbot:
Situación baseline:
- 10M requests/mes (chatbot conversacional)
- Llama 3.1 70B en 4x A100 GPUs
- Latencia P50: 2.5 segundos por respuesta
- Coste inferencia estimado: Valor mensual significativo en infraestructura cloud
Con speculative decoding (vLLM + draft model):
- Latencia P50: 1.0 segundo (2.5x improvement)
- Reducción tiempo GPU: 60% por request
- Capacity: Puedes servir 2.5x requests con mismo hardware
- Ahorro infraestructura: Significativo o capacidad para crecer sin escalar hardware
ROI calculation:
- Engineering time: 5 días ML engineer
- Break-even: ~2-3 semanas en ahorro infraestructura
- ROI 12 meses: Muy positivo considerando ahorro continuo
► Trade-Off: Latencia vs Throughput
El trade-off fundamental de speculative decoding: optimizas latencia individual a costa de throughput máximo (en algunos escenarios).
⚠️ Consideración throughput:
Mientras reduces latency 2x para usuarios individuales, el throughput aggregate (total tokens generados por segundo) puede reducirse 10-30% en batch sizes altos. Esto es acceptable si tu constraint es latency (user experience), no capacity (QPS máximo).
Troubleshooting: Problemas Comunes y Soluciones
10. Troubleshooting: Problemas Comunes y Soluciones
Estos son los problemas más comunes reportados en GitHub issues de vLLM, llama.cpp y producción deployments, con soluciones verificadas.
► Problema #1: Acceptance Rate Invisible en vLLM
🐛 Síntoma:
"No puedo ver el acceptance rate en ningún lado. ¿Cómo sé si speculative decoding funciona?"
GitHub Issue #7301 vLLM, Agosto 2024
Causa raíz: vLLM
► Problema #2: Slowdown Inesperado en A100 (llama.cpp)
🐛 Síntoma:
"Con acceptance rate 0.44, speculative decoding es MÁS LENTO (50 tokens/s) que autoregressive normal (75 tokens/s) en A100. En Mac M1 funciona bien."
GitHub Issue #3649 llama.cpp, Octubre 2023
Causa raíz: Bug llama.cpp GPU utilization. Weights offloaded a GPU pero GPU no se usa durante speculative decoding phase. CPU bottleneck.
Soluciones:
- Solución #1: Usar vLLM en lugar de llama.cpp para production deployments (no tiene este bug)
- Solución #2: Si debes usar llama.cpp, actualizar a versión más reciente (bug parcialmente resuelto en 2024)
- Solución #3: Para A100, verificar que draft model también esté offloaded a GPU con `-ngl` flag
⚠️ Lección: Siempre benchmarkea en tu hardware target específico. Performance en M1 Mac NO predice performance en A100. Diferencias arquitectura (unified memory vs HBM) causan comportamientos radicalmente distintos.
► Problema #3: Resource Contention Draft + Target (TensorRT-LLM)
🐛 Síntoma:
"Draft y target models pelean por recursos GPU cuando ejecutan en misma GPU. Performance degrada en lugar de mejorar."
Baseten Blog, "How we built production-ready speculative decoding with TensorRT-LLM", Diciembre 2024
Causa raíz: TensorRT-LLM NO maneja resource contention automáticamente. Necesitas custom async execution loop sincronizado.
Solución Baseten (production-verified):
- Ejecutar draft model en async loop separado (non-blocking)
- Bufferear tokens especulativos en queue
- Target model consume batch de queue cuando esté ready
- Implementar backpressure si draft genera más rápido que target verifica
- Usar CUDA streams separados para draft vs target
Alternativa: vLLM maneja esto automáticamente con PagedAttention scheduler. Si no tienes equipo con expertise CUDA/C++, usa vLLM.
► Problema #4: TTFT (Time-to-First-Token) Degradation
⚠️ Síntoma:
"El primer token tarda MÁS con speculative decoding que sin él. Los siguientes tokens son más rápidos, pero TTFT es crítico para UX."
Causa raíz: Draft model debe hacer prefill también. Overhead inicial de cargar dos modelos en lugar de uno.
Mitigaciones:
- Prefill optimization: Usar chunked prefill (vLLM feature) para reducir TTFT
- EAGLE-3: Self-speculative elimina overhead draft model prefill separado
- Prompt caching: Combinar con speculative decoding para amortizar prefill cost
- Trade-off acceptable: +50ms TTFT pero -60% latency total (usuarios perciben mejora)
🎯 Conclusión: Implementa Speculative Decoding Hoy
Speculative decoding es la técnica de optimización de inferencia LLM más impactante de 2024-2025. Con 2-4x speedup sin pérdida de calidad, es aplicable a la mayoría de casos de uso production: chatbots, generación código, agentes autónomos, Q&A técnico.
Los puntos clave que debes recordar:
- Draft model selection es crítico: 1.64%-5% del target size, misma familia arquitectónica, acceptance rate >0.55
- vLLM es el framework dominante: Fácil implementación, production-ready, Red Hat Speculators compatible
- Hyperparameters por caso de uso: 3-5 tokens conversational, 6-8 código, 5-7 agentes
- Monitoreo acceptance rate obligatorio: Si cae
El ROI es claro: 5 días engineering time para implementación vLLM básica, break-even en 2-3 semanas por ahorro infraestructura, benefit continuo mes a mes. Para startups SaaS con latency-sensitive products, es no-brainer.
Próximos pasos recomendados:
- Benchmarkea tu sistema actual (baseline latency P50/P90, throughput, costes)
- Selecciona draft model apropiado (usa tabla tamaños 1.64%-5% del target)
- Implementa vLLM speculative decoding en staging (config básica 5 tokens)
- Mide acceptance rate real con production-like data (target >0.55)
- Tunea hyperparameters basado en acceptance rate y latency metrics
- Deploy a producción con monitoring Prometheus (acceptance rate, latency, goodput)
- Define alertas y rollback strategy si degradation detectada
Si necesitas ayuda técnica implementando speculative decoding en tu infraestructura LLM, mi servicio MLOps & Deployment de Modelos incluye draft model selection, vLLM configuration, Kubernetes deployment, Prometheus monitoring setup, y troubleshooting production. Contáctame para consulta técnica gratuita.
¿Necesitas Optimizar la Latencia de tus LLMs en Producción?
He implementado speculative decoding para startups SaaS reduciendo latencia 2-4x sin perder calidad. Te ayudo con selección de draft models, configuración vLLM/TensorRT-LLM, y deployment completo.
Solicitar Consultoría MLOps →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Consulting y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud production-ready.